

一个方法教你构建abaqus小型并行计算集群平台-凯发网站
本文介绍了一个基于 em64t 硬件构架、双路 intel xeon 处理器、linux 操作系统和 64 位 abaqus 软件的 32cpu 并行计算集群平台的构建方法。以岩土工程动力分析模型为例,测试了集群各构件对集群整体性能的影响。
当代并行计算系统的构架
目前常用的并行计算机是对称多处理机(smp)和集群系统(cluster)。常见的搭载单颗多核处理器的桌面个人计算机就属于 smp;cluster 是一种通过局域网络将多台计算机连接起来协同工作的并行计算系统,可以用普通个人电脑(pc)、工作站(workstation)或者 smp 来组建 cluster。smp 与 cluster 最大的区别在于:smp 中内存地址具有单地址空间,各处理器可以平等地调用共享内存、i/o 设备和操作系统等各种资源;cluster 中内存实际分布在各个节点上,处理器读取本地节点的内存时数据通过总线传输,延时低,处理器读取其它节点的内存时数据通过局域网络传输,延时高。smp 支持的最大处理器数一般不超过 10 个,因此 smp 只能作为小型的并行计算系统。cluster利用局域网络进行处理器间通信的方法虽然能提高并联的处理器数,但也因局域网络的带宽和延时限制了集群的性能,目前集群技术适合搭建 100 颗处理器以下级别的并行计算系统。
目前 smp 结构的服务器一般是搭载多核处理器的双路或四路服务器,但真正的八路或十六路服务器产品非常少见。一些 smp 结构的小型机可以并联更多的处理器,但是其价格昂贵,后期维护复杂。cluster 可以使用商业化大生产的多路服务器来构建。双路或四路服务器是很好的选择,该类服务器价格低廉、性能优异,用来构建 cluster可以获得很好的性能/价格比。所以在科学计算领域,cluster 非常流行,在 top500 中很大一部分并行计算系统都是 cluster。
此外还有一些阵列处理机、向量处理机,可能不兼容常用的 x86 程序,所以应用上具有局限性。目前提出的gpu 加速技术,需要开发新的程序来使用该技术,用在运行商业程序的集群上也不适用。
基于 abaqus 软件的数值模拟并行计算集群平台的建立
1.1 集群系统的结构
集群中的每台计算机设备都称为集群的节点(node),有时各节点在功能上具有分工,那么各节点可以依照功能划分为管理节点、计算节点、i/o 节点等;有时一个节点也可能实现多个功能,例如小型集群可以将 i/o、存储、管理等功能都放在一个节点上,这个节点就可以称为主节点。与 smp 相比,集群更具有可扩放性:增加集群中处理器数量只需要增加集群的节点。本文中构建的集群采用机架式设备组建,按功能分为四类节点:计算节点、管理节点、存储节点和网络节点。
其具体的硬件配置见表 1。其拓扑结构图见图 1。图 1 显示了该集群系统及其主要附属设备。除集群各类节点外,电源系统、监视系统和冷却系统也是维持集群正常工作的重要附属设备。
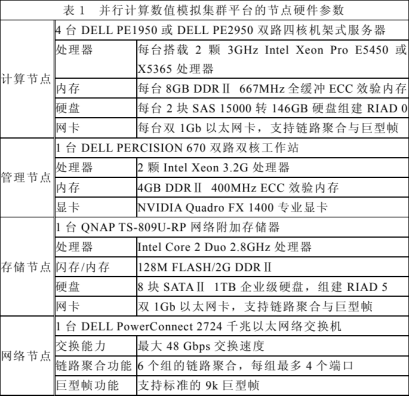
图1集群系统的结构图
1.2 计算节点的选择
在构建基于 abaqus 软件并行计算数值模拟集群平台时,硬件选择方面如何兼顾显式计算和隐式计算是首先需要考虑的问题。显式算法和隐式算法在并行计算性能特性方面有很大的差异。显式算法的并行性能好,但是,如果模型网格划分很细致,则计算的时步需要取值很小;隐式计算的并行性能稍差,cpu 间通信多,但模型所取的计算时步和网格尺寸都可以大一些,时间步长甚至是同类问题显式算法模型的 1000 倍。表 2 总结了隐式算法和显式算法的特点,以及对计算机硬件的要求。
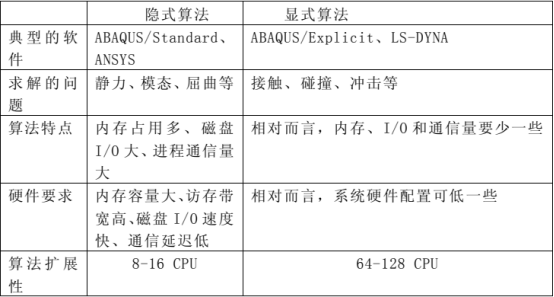
表2隐式算法与显式算法的特性比较
虽然隐式算法的并行计算扩展性差,但是可以使用高主频的处理器来加速计算。本集群使计算节点采用高性能计算节点,但是配置了较少的节点数,在 cpu 主频和 cpu 个数两个性能参数上取得平衡,从而兼顾隐式算法和显示算法。
中央处理器(cpu)是决定计算机性能的核心部件。计算机根据 cpu 支持的指令集的差异分为:复杂指令系统计算机(cisc)和精简指令系统计算机(risc)。常用的 intel xeon 和 amd option 处理器隶属于 cisc/ia-32(也称为x86-64 或 emt64)构架。cisc 的发展历史悠久,可运行于 cisc 上的程序非常丰富,该构架下的处理器研发工作也非常迅速。intel itanium 处理器隶属于 cisc/ia-64 构架,但不兼容 32 位程序,存在应用局限性。同时 intel itanium处理器主频低,其 abaqus 计算性能反而不如高频的 x86-64 处理器。ibm power 处理器隶属于 risc 构架。虽然risc 在计算效率上高于 cisc,但其相应程序的开发要慢于 cisc。由于 cisc/ia-64 和 risc 非通用性,计算速度相同的处理器产品中 x86-64 的价格最低廉。在 top500 中采用 x86-64 处理器的集群所占比例很大。
综合考虑计算机软件的通用性、设备价格、设备性能和解决设备故障的难易性,intel xeon 或 amd option处理器是很好的选择。这两类处理器都属于 64 位处理器,也兼容 32 位程序。
判断 x86-64 处理器性能的主要指标是处理器核心类型、主频、总线带宽(或类似的技术)、缓存容量。但是在某一地铁隧道地震效应数值计算中(使用 abaqus/standard 求解器),intel xeon x5365 处理器的计算速度要高于 intel xeon e5450 处理器。在其它一些使用 abaqus/standard 求解器的测试中,intel xeon 5400 系列处理器的计算速度要高于 intel xeon 5500 系列处理器。所以上述主要指标只是处理器性能的参考,为 abaqus 集群选择处理器需要做贴近实际运用的测试。
存储节点对计算速度的影响
abaqus 软件在计算中将产生临时文件和结果文件,这些文件需要存储在磁盘空间上。一个集群系统的磁盘空间可能是局部存储类型的,这类空间只允许某一个节点访问;也可能是全局存储类型的,这类空间允许所有节点访问。每个节点上装载的硬盘是局部存储,但是可以通过网络文件系统(nfs)服务通过局域网络上实现磁盘共享,共享的磁盘空间就是全局存储空间。
在《abaqus version 6.7 pdf documentation》中称临时文件和结果文件可以存储在任意类型的空间上。实际中一般使用局部空间存储临时文件,使用全局空间存储结果文件。这主要基于:1. 临时文件读写频繁,存储在读写速度快的局部存储上可以提高计算速度。2. 结果文件体积巨大,需要大容量存储器。构建全局存储空间的代价要小于构建局部存储空间的代价,同时全局存储空间易于统一管理。使用全局空间存储结果文件是经济、易管理的。
在 abaqus 集群使用中,一般是某节点通过 nfs 服务端程序为所有节点提供共享存储空间。提供共享存储空间有 3 个方法:1. 某管理节点或计算节点共享本地磁盘。但是服务器的硬盘槽位数量有限,更换硬盘操作繁琐;2. 通过光纤网络将 fc-san 挂载到某管理节点或计算节点上,然后由管理节点或计算节点操作 fc-san 来提供nfs 服务。但是此时 fc-san 上的数据传输将通过光纤网络和集群内部局域网两个网络,传输过程复杂、存在传输延时;3. 采用网络附加存储器(nas)提供 nfs 服务。nas 即专门为提供文件服务而优化系统的服务器,文件读写性能高。其可以直接连接到集群内部局域网上。同时更换硬盘、数据备份、文件管理也非常方便。
从共享文件管理性、存储容量可扩充性、数据传输速度方面综合考虑,可以使用 nas 为 abaqus 集群系统提供 nfs 服务。
nas 的处理器、内存都是其性能指标。nas 的另外一个性能指标是其网络性能,如果是以太网络接口,其网络带宽、是否支持巨型帧、是否支持链路聚合都对 nas 性能产生影响。在集群使用中可能同时有多个节点要求读写 nas 上存储的数据,nas 的工作负荷大,其性能将影响到集群系统整体的计算速度。
在对 qnap ts-439 pro turbo nas 和另一款 nas 产品做对比测试后发现:nas 的性能对集群系统计算性能影响巨大。另一款 nas 产品支持 1gb 以太网络,但整体性能参数较低:不支持链路聚合,最大支持 7.5k 巨型帧。
测试算例使用某一地铁隧道地震效应模型(使用 abaqus/standard 求解器),同时 nas 设备开启了所有能够提高网速的功能。测试数据见图 2。
本对比测试分 3 组:a 组-高负荷下使用 nas 的 abaqus 计算;b 组-低负荷下使用 nas 的 abaqus 计算;c组-不使用 nas 的 abaqus 计算。
a 组-高负荷下使用 nas 的 abaqus 计算:同时进行 7 个 abaqus 计算任务,每个计算使用 4cpu,7 个计算任务都使用 nas 设备来存储共享文件。
b 组-低负荷下使用 nas 的 abaqus 计算:只进行 1 个 abaqus 计算任务,使用 4cpu,该计算任务使用 nas设备来存储共享文件。
c 组-不使用 nas 的 abaqus 计算:只进行 1 个 abaqus 计算任务,使用 4cpu,该计算任务不使用 nfs 服务,将文件直接存储在本地磁盘上。此种情况是最优情况,但调用多个节点并行计算时必需使用 nfs 服务,即在集群构架下最优情况不适用于大型的并行计算。
图 2 磁盘性能对计算速度的影响
本对比测试中 b 组 ts-439 较 c 组性能计算速度下降 10.4%;a 组 ts-439 较 b 组 ts-439 性能下降 20.6%。b组 ts-439 与 c 组的性能比较证明使用 ts-439 nas 带来的性能影响可以接受;a、b 组 ts-439 性能比较证明 ts-439 nas 在高负荷下的性能表现可以接受。但是另一款 nas 产品带来的性能下降是无法接受的:低负荷下造成计算速度下降 31.3%,高负荷下造成计算速度下降 63.6%!实际上 qnap ts-439 pro turbo nas 并不是一款高端产品,qnap 和 buffalo 的高端产品性能将更好,可以作为集群的存储设备。
网络对计算速度的影响
通信性能对集群整体的性能具有决定性的影响,某些情况下集群网络的性能是整个集群系统性能的瓶颈。采用何种网络互连技术连接节点以及如何优化网络提高网络性能是构建集群平台的重要工作内容。
目前,集群系统中常用的网络有以太网络(gigabit ethernet,简称 gige)、myrinet 网络、infiniband 网络。simulia 公司提供的资料[3]显示:对应于 abaqus 软件的应用,各种网络互连技术在互连 32 个以下处理器时性能差距不大。对于一个小型集群,使用 infiniband 网络替换千兆以太网络带来的性能提升不大。因此集群平台采用千兆以太网络传输节点间的通信是经济可用的。
若考虑到保持以太网络的兼容性,则对于以太网络的优化目前主要有 4 种途径:一是修改 linux 内核中的tcp/ip 协议参数以及开启巨型帧;二是链路聚合提高网络带宽;三是减少用户空间与内核空间的数据拷贝次数;四是减少中断响应次数。由这 4 种优化思路出发产生了用于以太网络优化的各种技术,在 linux 系统中它们分别称为:1. tcp/ip 协议栈优化(tcp tuning)和巨型帧(jumbo frames);2. 双网卡绑定技术(bonding);3. 零拷贝(zero
copy);4. 使用新的 api 函数(new api 简称 napi);5. tcp/ip 减负引擎(toe)。表 3 总结了这 5 种方法加快网速的原理。
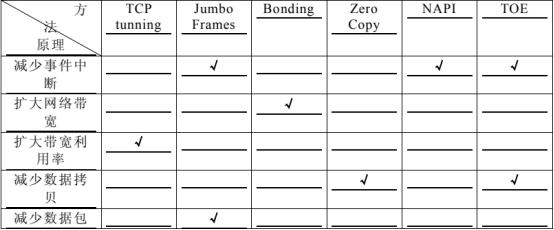
表 3 以太网络优化方法的原理
对各种方法的优化原理做比较后,确定选择两种方法对集群局域以太网络做组合优化:1. tcp/ip 协议栈优化和巨型帧;2. 双网卡绑定。制定方案的原因有二:1. 这两种优化方法组合使用,除不能实现减少数据拷贝过程外,其它方面都有所优化;2. 该组合优化方法较易实现,优化后的系统管理也较为方便。
为了测试两种优化方法对集群平台性能的影响,本文采用了一个垂直上下交叉隧道 abaqus 有限元模型作为算例。本模型双向水平地震波输入,在计算中隧道单元出现了塑性变形,反映了材料非线性的特性,计算算法选择隐式算法,使用 standard 求解器计算,在动力学问题中具有一定的代表性。测试了使用双节点(16 个处理器核心)和三节点(24 个处理器核心)时的计算速度,共做 6 次测试并获得相应的 dat 文件。各次测试条件见表 4。
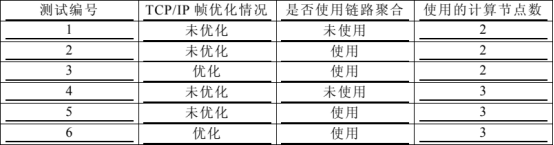
表 4 集群平台性能测试的条件
图 3 是根据表 4 的数据制作的 6 个测试的计算耗时散点图,图 3 中以测试 2 的耗时数据为基准对 6 个测试的total cpu time 和 wallclock time 进行归一化,共获得 12 个数据点,测试 n 的相对耗时等于测试 n 的耗时除以测试 2 的耗时。
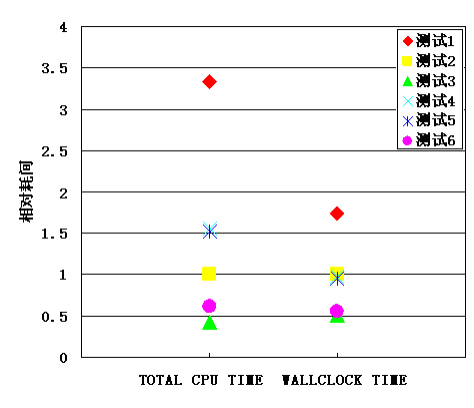
图 3 6 次测试的相对耗时散点图
图 3 显示 6 次测试的相对 total cpu time 离散性比较高,测试 1 的相对 total cpu time 等于 3.34,是最大值;测试 3 的等于 0.42,是最小值。两者之间相差约 7 倍。相对 wallclock time 离散性比较小,测试 1的相对 wallclock time 等于 1.74,是最大值;测试 3 的等于 0.51,是最小值。6 个测试的相对 total cpu time排序不同于相对 wallclock time 排序,但两个排序中只有测试 2 的次序不同。可以认为不同测试条件下 total cpu time 和 wallclock time 的变化趋势基本相同。两个耗时序列基本一致,由此认为,测试中的其它影响因素(这些影响主要体现在 wallclock time 中) 对各次测试影响相同,故选取 wallclock time 作为衡量该集群平台计算时耗的标准。wallclock time 是综合了各种影响因素的 abaqus 求解器进程实际运行时间,它
是用户等待计算任务结束花费的时间。
图 3 中各次测试的相对 wallclock time 间的差异表明:计算条件对于计算速度影响很大。首先,图 3 中测试 1 耗时大于测试 2、测试 2 耗时大于测试 3,测试 4、测试 5、测试 6 的耗时关系也相同,这说明链路聚合和tcp/ip 栈优化都可以提高数值计算速度。测试 1 的 wallclock time 是测试 3 的 3.43 倍,这说明集群网络性能对 abaqus 软件的计算速度影响巨大,链路聚合和 tcp/ip 栈优化对网络的优化效果很好。其次,图 3 中测试 1的耗时大于测试 4,测试 2 的耗时小于测试 5,但测试 3 的耗时小于测试 6,这说明集群网络性能越好,计算任务最适宜调用的处理器数越少,良好的集群网络可以减少消耗的软硬件资源并获得同样的计算速度。
结语
本集群系统已经实际应用,在土木工程动力分析领域完成了涉及场地地震效应、流固耦合效应、建(构)筑物间的相互作用等问题的数值模拟实验。虽然集群在显式算法、隐式算法,小规模模型、大规模模型的并行计算效率上差别较大,但是整体而言集群技术是能够缩短计算时间,从而提高工程设计、科研研究进度的。
本文介绍了集群系统的部件,以及维持集群系统正常运作的附属设施。文中介绍了兼顾显式算法和隐式算法集群的集群构建方法。文中分析了决定集群性能的 cpu 的选取方法,对集群系统中的存储节点、网络节点的部分性能指标做了阐述。测试了存储节点、网络节点的性能对整体集群性能的影响。
本文阐述的构建方法是针对小型 abaqus 集群系统,其构建思路也适用于构建大型集群系统,也适用于构建运行其它商业软件的集群系统。本文仅是引玉之抛砖,希望能够为广大希望使用上并行计算功能但对并行计算系统存在疑惑的读者介绍一些构建系统的心得,希望能够推动高性能计算应用层面的发展。






-
[cst] cst软件qfn封装仿真 --- s参数,3d bond
2024-06-07
-
[cst] cst纳米光学 --- lspr局部等离子激元共振,消光截
2024-06-07
-
2024-06-07
-
2024-06-07
-
[有限元知识] abaqus软件分析指南394:涉及孔隙流体压力的程序
2024-06-06
-
[有限元知识] abaqus软件分析指南393:热通量与涉及热自由度的程序
2024-06-06
-
[有限元知识] abaqus软件分析指南392:涉及机械自由度的程序
2024-06-06
-
[abaqus] 谈谈影响abaqus软件影响分析时间的因素有哪些
2024-06-05
-
2024-06-05
-
2024-06-05
-
2023-08-24
-
[abaqus] abaqus如何建模?abaqus有限元分析教程
2023-07-07
-
2023-08-29
-
[abaqus] 有限元分析软件abaqus单位在哪设置?【操作教程】
2023-09-05
-
[abaqus] 如何准确的评估真实行驶工况条件下的空气动力学性能
2020-11-19
-
[abaqus] abaqus单位对应关系及参数介绍-abaqus软件
2023-11-20
-
[abaqus] abaqus里面s11、s12和u1、u2是什么意思?s和
2023-08-30
-
[abaqus] abaqus软件教程|场变量输出历史变量输出
2023-07-18
-
2023-07-26
-
[abaqus] abaqus软件中interaction功能模块中的绑定接
2023-07-19
-
2024-06-07
-
[有限元知识] abaqus软件分析指南394:涉及孔隙流体压力的程序
2024-06-06
-
[有限元知识] abaqus软件分析指南393:热通量与涉及热自由度的程序
2024-06-06
-
[有限元知识] abaqus软件分析指南392:涉及机械自由度的程序
2024-06-06
-
[有限元知识] abaqus软件分析指南391:参数研究结果
2024-05-30
-
[有限元知识] abaqus软件分析指南390:参数化研究设计的生成和执行
2024-05-30
-
2024-05-30
-
[行业资讯] 可持续创新|行业首家“国家级工业设计中心”的发展秘笈
2024-05-29
-
[行业资讯] 上课啦!达索cst核心模块及emc仿真培训(深圳站)即将开
2024-05-29
-
[有限元知识] abaqus软件分析指南388:参数样本组合
2024-05-28
-
 汽车交通
汽车交通 -
 风能电源
风能电源 -
 船舶机械
船舶机械 -
 生物医疗
生物医疗
-
 土木建筑
土木建筑 -
 新能源
新能源 -
 高科技
高科技



地址: 广州市天河区天河北路663号广东省机械研究所8栋9层 电话:020-38921052 传真:020-38921345 邮箱:thinks@think-s.com



凯发k8官方网娱乐官方 copyright © 2010-2023 广州思茂信息科技有限公司 all rights reserved. 粤icp备11003060号-2